Comparisons
Local LLM Pi 5 vs N100 Voice Privacy 2026
Benchmark-style comparison of Raspberry Pi 5 versus Intel N100 mini PCs for local LLM voice assistants with Home Assistant: RAM, thermals, tokens per second, and privacy.
Quick answer: Raspberry Pi 5 or N100 mini PC for a local voice + LLM stack?
Use Pi 5 8 GB for light stacks (Whisper small + compact LLM) in space-constrained installs. Choose an N100 mini PC with 16 GB RAM when you want faster token generation, headroom for larger quantizations, and better thermals under continuous voice traffic.
Source: Ollama documentation
Executive Summary
This article narrows the hardware question compared to our broad best local LLMs and Pi vs mini-PC vs NAS buying guide: voice-shaped workloads (short prompts, frequent turns, Whisper or similar STT) running next to Home Assistant.
Bottom line: Pi 5 wins on cost and watts; N100 wins on sustained inference and RAM headroom.
Voice pipeline components (local)
| Stage | Typical software | Hardware sensitivity |
|---|---|---|
| Wake / VAD | Lightweight on-device | Low |
| STT | Whisper.cpp / faster-whisper | CPU + RAM bandwidth |
| LLM | Ollama, llama.cpp, etc. | CPU AVX2, RAM size |
| TTS (optional) | Piper, Coqui local | Medium |
Follow the end-to-end pattern in Whisper + Ollama + Home Assistant.
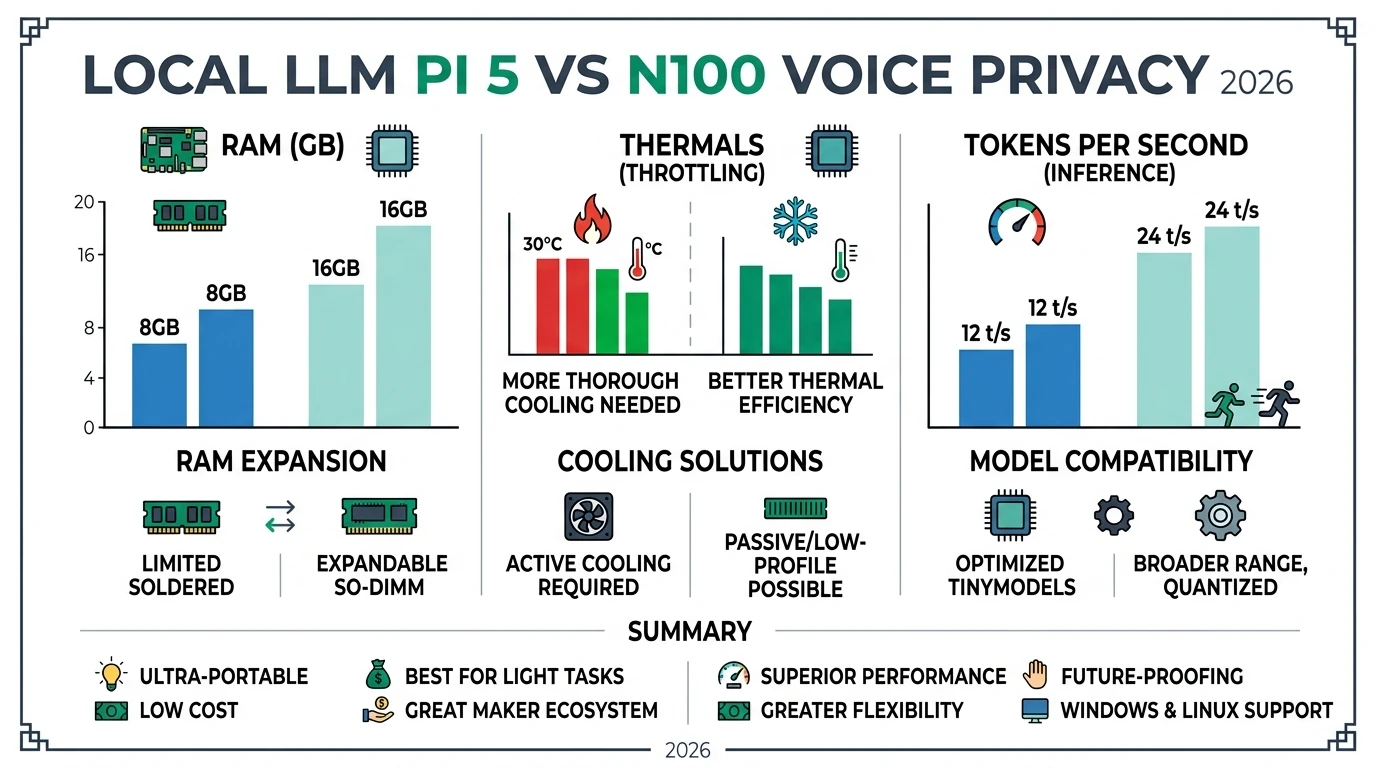
Raspberry Pi 5 (8 GB) — when it is enough
| Strength | Limit |
|---|---|
| Low idle power | Thermal throttle under long LLM runs without cooling |
| GPIO / HAT ecosystem | 8 GB RAM caps model size |
| Price | USB storage bandwidth vs NVMe mini-PCs |
Best for: one-room assistant, aggressively quantized models, off-peak generation (not constant chat).
Intel N100 mini PC — when to step up
| Strength | Limit |
|---|---|
| Higher sustained CPU throughput | Higher idle power than Pi |
| 16 GB RAM common | Fan noise varies by chassis |
| NVMe + RAM upgrades | Physical footprint |
Best for: whole-home voice, larger context windows, running Frigate or other services on the same box—compare AI accelerators in Coral vs Hailo vs GPU.
Planning table (order-of-magnitude)
| Workload profile | Lean Pi 5 8 GB | Lean N100 16 GB |
|---|---|---|
| Whisper base/small + 3B–4B Q4 LLM | Comfortable | Overkill but smooth |
| 7B class model + margin for HA | Tight | Recommended |
| Always-on multi-user voice | Risky thermals | Preferred |
Privacy comparison (local inference)
| Topic | Pi 5 | N100 |
|---|---|---|
| Data leaves LAN? | No if configured locally | Same |
| Firmware attack surface | ARM SBC supply chain | x86 UEFI + ME (mitigate with updates) |
| Disk encryption | Supported via Linux | Easier on standard NVMe setups |
Both beat cloud assistants on data residency when STT and LLM stay on-LAN.
Checklist
- Budget RAM first—voice + LLM + HA addons add up fast.
- Plan cooling: Pi 5 needs a case with a heatsink for sustained loads.
- Use the same quantization across A/B tests when comparing hardware.
- Keep Whisper and LLM on the same host to avoid LAN audio streaming.
- Snapshot backups before experimenting with Ollama model swaps.
FAQ
Frequently Asked Questions
Is Apple Silicon better than N100?
Apple hardware can be fast for local ML but is a different integration story for Home Assistant servers—our focus here is common self-hosted x86/ARM boxes.
Can I use a GPU instead?
Yes for some stacks; see GPU vs TPU for Frigate overlap decisions.
Will Pi 5 run a 70B model?
Not realistically for interactive voice—stick to small/medium quantizations aligned with RAM.
Does N100 beat Ryzen in this use case?
Depends on model and AVX paths—N100 is a common efficient choice, not the only one.
Should voice and Frigate share one box?
Possible on N100 with careful CPU pinning; Pi 5 often struggles with both at high load.
Primary sources
| ID | Source | URL |
|---|---|---|
| 1 | Ollama | github.com/ollama/ollama |
| 2 | faster-whisper | github.com/SYSTRAN/faster-whisper |
Conclusion
For local voice + LLM in 2026, Pi 5 remains the gateway drug to private assistants; N100 mini PCs are the workhorse when you outgrow thermals and RAM. Align purchase with model size, concurrent services, and noise/power constraints—not benchmark bragging rights.